Defining modeling tasks#
Every Hub is organized around “modeling tasks” that are defined to meet the needs of a project. Modeling tasks are defined for a hub in the tasks.json configuration file for a hub. Modeling tasks are defined for either a single round, or for multiple rounds that are distinguished by different values of a specific task_id variable. The three components of modeling tasks are task ID variables, output types, and target metadata. Broadly speaking these three components function as follows:
The task_ids object defines both labels for columns in submission files and the set of valid values for each column. Any unique combination of the values define a single modeling task, or target.
The output_type object defines accepted representations for each task. More on the different output types can be found in this table.
The target_metadata array provides additional information about each target.
task ID variables#
Hubs typically specify that modeling outputs (e.g., forecasts or projections) should be generated for each combination of values across a set of task ID variables. For modeling exercises where the model outputs correspond to estimates or predictions of a quantity that could in principle be calculated from observable data, these task ID variables should be sufficient to uniquely identify an observed value for the modeling target that could be compared to model outputs to evaluate model accuracy. This is discussed more in the section on target (a.k.a. truth) data.
Because they are central to Hubs, task ID variables serve several purposes:
They are used in the Hub metadata to define modeling tasks of the hub
They are used in model outputs to identify the modeling task to which forecasts correspond
They are used in the specification of target data and methods to calculate “ground truth” target data values, to allow for alignment of model outputs with true target values The relationships between these items are illustrated at a high level in the following diagram; sections to follow provide more detail.
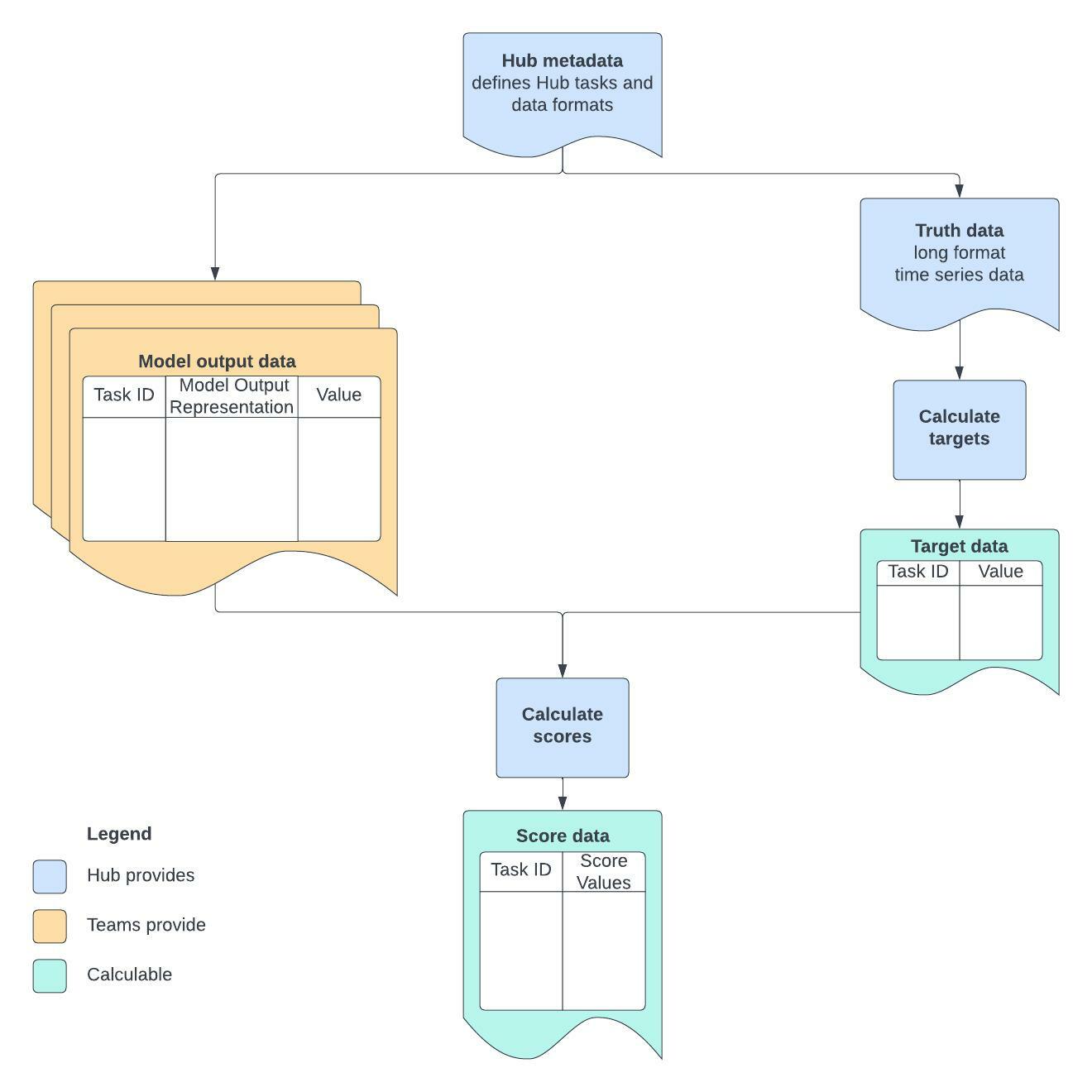
The figure shows that Hub metadata and target data are specified by the hub itself, along with any necessary functions to calculate scores or “observed values” from target data. Teams provide model output data that must conform with standards identified in the Hub metadata.#
Usage of task ID variables#
Task ID variables can be thought of as columns of a tabular representation in a model output file, where a combination of values of task ID variables would uniquely define a row of data.
We note that some task ID variables are special in that they conceptually define a modeling “target” (these are referred to in the tasks metadata as a target_key). In our Running Example 1, the task ID variables are target, location, and origin_date. In this example, target is the target key and can only take on one value “inc covid hosp”. In other examples, (such as Running Example 3) more than one variable can serve as target keys together. In example 3,both ‘outcome_variable’ and ‘outcome_measure’ make up the target keys.
Some task ID variables serve specific purposes. For example, every hub must have a single task ID variable that uniquely defines a submission round. It has become a convention to use a task ID like origin_date or forecast_date for this purpose, although in practice hubs could use other task ID variables for this purpose. In Running Example 1, this task ID is origin_date.
In general, there are no restrictions on what task ID variables may be named, however when appropriate, we suggest that Hubs adopt the following standard task ID or column names and definitions:
origin_date: the starting point that can be used for calculating a target_date via the formulatarget_date=origin_date+horizon*time_units_per_horizon(e.g., with weekly data,target_dateis calculated asorigin_date+horizon* 7 days).forecast_date: usually defines the date that a model is run to produce a forecast.scenario_id: a unique identifier for a scenariolocation: a unique identifier for a locationtarget: a unique identifier for the target. It is recommended, although not required, that hubs set up a single variable to define the target (i.e., as a target key), with additional detail specified in thetarget_metadatasection of the tasks metadata.target_variable/target_outcome: task IDs making up unique identifiers of a two-part target. These task can be used in hubs that want to split up the definition of a target across two variables. In this situation, both task IDs eill de specified as target keys in thetarget_metadatasection of the tasks metadata.target_date/target_end_date: for short-term forecasts, the synonymous task IDstarget_date/target_end_datespecify the date of occurrence of the outcome of interest. For instance, if models are requested to forecast the number of hospitalizations that will occur on 2022-07-15, the target_date is 2022-07-15.horizon: The difference between the target_date and the origin_date in time units specified by the hub (e.g., may be days, weeks, or months)age_group: a unique identifier for an age group
Note
We encourage Hubs to avoid redundancy in the model task IDs. For example, Hubs should not include all three of target_date, origin_date, and horizon as task IDs because if any two are specified, the third can be calculated directly. Similarly, if a variable is constant, it should not be included. For example, if a Hub does not include multiple targets, target could be omitted from the task IDs.
As Hubs define new modeling tasks, they may need to introduce new task ID variables that have not been used before. In those cases, the new variables should be added to this list to ensure that the concepts are documented in a central place and can be reused in future efforts.
Output types#
The output_type object defines accepted representations for each task. More on the different output types can be found in this table.
Target metadata#
Target metadata is an array in the tasks.json schema file that defines the characteristics of each target.
It is composed of the following fields:
target_id: a short description that uniquely identifies the target.target_name: a longer, human readable description of the target, which could be used as a visualization axis label.target_units: the unit of observation used for this target.target_keys: a set of one or more name/value pairs that must match a target defined in thetask_idssection of the schema. Each value, or the combination of values if multiple keys are specified, defines a single target value.description: a verbose explanation of the target, which might include details on the measure used for the target or a definition of ‘rate’, for example.target_type: the target’s statistical data type. The following table lists the possible values fortarget_typeand theoutput_typewith which they can be used. We note that for the binary data type row, mean and medianoutput_typeare X’ed for definitional consistency, but in practice the hubverse recommends using pmf or sampleoutput_typeas a more natural way to represent these values.
|
mean |
median |
quantile |
cdf |
pmf |
sample |
|---|---|---|---|---|---|---|
continous |
X |
X |
X |
X |
- |
X |
discrete |
X |
X |
X |
X |
X |
X |
nominal |
- |
- |
- |
- |
X |
X |
binary |
X |
X |
- |
- |
X |
X |
date |
X |
X |
X |
X |
X |
X |
ordinal |
- |
X |
X |
X |
X |
X |
compositional |
X |
X |
- |
- |
- |
X |
is_step_ahead: a Boolean value that indicates whether the target is part of a sequence of values. Ifis_step_aheadis true, then this field is required and defines the unit of time steps. Ifis_step_aheadis false, then this should be left out and/or will be ignored if present.time_unit: the units of the time steps in terms of day, week, or month.
Example#
Here is an example of how the target metadata fields might appear in the tasks.json schema for a Hub whose target is incident covid hospitalizations.
"target_metadata": [
{
"target_id": "inc covid hosp",
"target_name": "Daily incident COVID hospitalizations",
"target_units": "count",
"target_keys": {
"target": "inc covid hosp"
},
"description": "Daily newly reported hospitalizations where the patient has COVID, as reported by hospital facilities and aggregated in the HHS Protect data collection system.",
"target_type": "discrete",
"is_step_ahead": true,
"time_unit": "day"
}
]